使用词向量和余弦相似度进行文本查重
Word2vec是一种用于自然语言处理的算法,它可以将文本中的单词表示为高维向量,这些向量可以被用来计算单词之间的相似度。而余弦相似度是一种用于计算向量之间相似度的度量方法,本文使用word2vec和余弦相似度结合的方法来进行文本的查重。
1. Word2Vec
1.1 基本思想
word2vec是一种基于神经网络的自然语言处理算法,通过学习大量文本语料库中单词的上下文信息,将单词转换为固定长度的高维向量。 \[ word \Longrightarrow \overbrace{[ \,\, 0.881,\,0.126,\,0.753,\,0.294,\,…\,,\,0.745\,\,]}^{embedding\,\,length} \] word2vec的基本思想是根据单词的上下文来学习单词的语义,这就意味着那些经常出现在相同上下文中的单词,映射到向量空间后其欧几里得距离会比较相近。比如给神经网络输入两个句子:He loved the big old house. He loved the large old house. 由于big和large出现在了相似的上下文中,因此神经网络会认为它们具有相近的语义,然后将它们映射到同一片向量空间中,当上下文相似的句子出现得越多,两个单词在向量空间中就会越接近。

图片仅作示例,实际上的词向量维度要远大于3
1.2 网络结构与两种模型
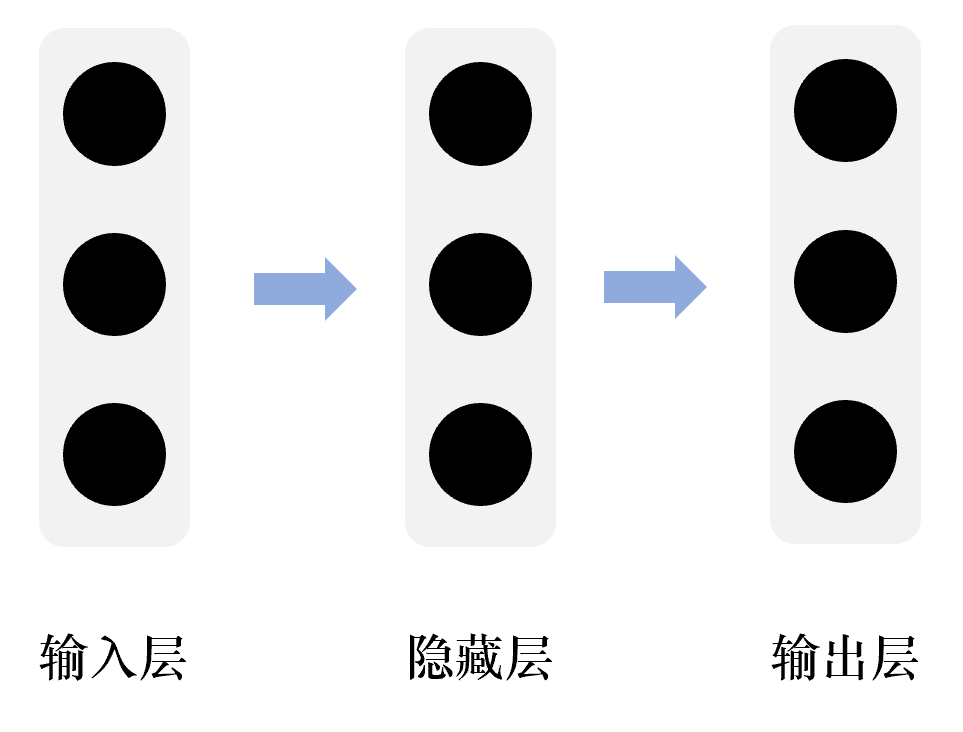
word2vec的网络结构相当简单,其仅仅包含输入层、一个隐藏层和输出层,我们需要的词向量可以从输入层到隐藏层的权重矩阵中提取,或者从隐藏层到输出层的权重矩阵中提取,具体训练过程下文描述。
word2vec有两种不同的模型,一种是Continuous Bag-of-Words Model(CBOW),一种是Contiguous Skip-gram Model(Skip-gram)。
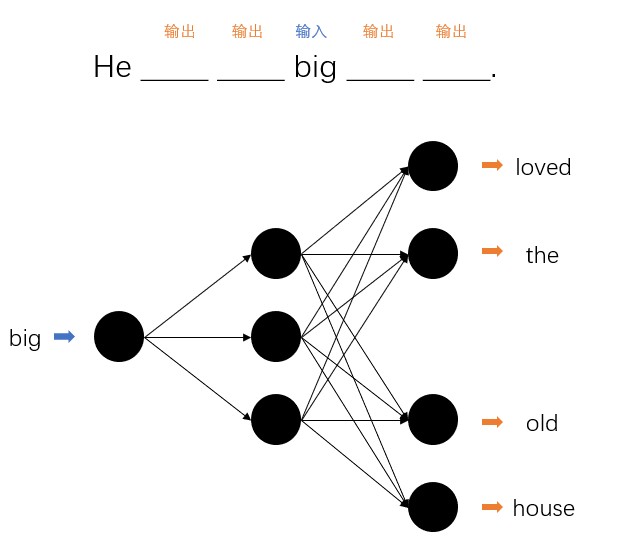
两种模型的区别主要在于输入和输出的形式。对于CBOW模型,其任务是根据上下文来预测当前出现的单词,相当于选词填空。首先从句子中选择一个词作为目标值,然后将指定长度的上下文作为输入来训练神经网络。比如:
而Skip-gram模型则相反,其要求输入一个词,然后根据这个词来预测指定长度的上下文。
1.3 训练过程
word2vec的输入向量和输出向量都用one-hot的形式给出,所谓one-hot向量,即向量中仅有一个元素为1,而剩余元素皆为0的向量。首先我们要确定我们字典(所有出现在训练集和测试集中的词的集合)的大小,然后给每一个词一个唯一的索引。则所有词的one-hot向量长度固定为字典大小,一个词的one-hot向量即索引处为1,其余处为0的向量。比如: \[ dict.length == 5\\ dict[2] = 'big'\\ big的one-hot向量:\,[0,0,1,0,0] \] 本项目使用的是CBOW模型,下面以CBOW模型为例来进行说明。
首先需要遍历整个训练集,找出所有出现的不同的字,并且给每一个字一个唯一的id。
然后在训练集中取出一段文本,使用一个滑动窗口(以大小为3的窗口为例)来取得一个个词袋,取中间的字作为目标值,剩下的字作为输入值。

对于每一个词袋,将其拆成输入字与目标字的一对,输入字和目标字都转换成one-hot向量,故训练时是一个一个字地输入到网络当中。

处理完训练集中所有文本后得到所有的输入-目标对,就可以进行训练,设字典大小为vocab_size,要获得的词向量的维数为embedding_size,则输入张量的形状为[batch_size, vocab_size],输出张量的形状为[batch_size, vocab_size],可以得到网络结构如下(pytorch):
1 | class VocabEmbedding(nn.Module): |
权重矩阵的形状为[vocab_size, embedding_size],当一个one-hot向量与其相乘时,因为one-hot向量中只有一个元素为1,所以计算结果实际上只与权重矩阵中的一行有关,计算输出值和目标值的误差后进行反向传播,也只有权重矩阵中的一行会被更新,因为其他行对输出值没有贡献。以vocab_size=5, embedding_size=7为例:

2. 余弦相似度
余弦相似度使用两个向量之间的夹角来衡量两个向量之间的相似程度,其计算公式如下: \[ similarity = cos\theta = \frac{\vec{x}·\vec{y}}{||x||\,·\,||y||} \] 欧氏距离更加注重两个向量在数值上的差异,余弦相似度则注重两个向量在方向上的差异。
3. 文本查重
3.1 句子的向量表示
通过word2vec,我们已经得到了每个字的向量表示,要得到每个句子的向量表示,我选择了直接将一个句子中所有字的向量简单加和,这样每个句子的向量都具有相同的长度,更加方便处理。
但是,这种做法丢失了字与字之间的时序信息,导致具有相同字但顺序不同的句子也被检测为相似,比如“国立武汉大学”和“学大汉武立国”在这种方法下会被认定为是完全相同的句子。

3.2 检测
将一篇文章分句后,再获得每个句子的向量,将这些向量组合成一个矩阵,这个矩阵就代表了这篇文章的内容。在组合成矩阵之前先将句子向量进行单位化,这样的话将两个文章的矩阵直接相乘就可以计算处两篇文章所有句子两两之间的余弦相似度。两篇文章的矩阵形状分别为[num_sentences, embedding_size],[embedding_size, num_sentence]。
